🔥[2025-7-5]: The outputs of different MLLM generators on OpenING can be accessed via Hugging Face. We are committed to making it easier and faster for users of our benchmark to conduct one-click tests. Stay tuned!
🔥[2025-2-27]: Our paper is accepted by CVPR 2025. Thanks to all contributors!
🔥[2025-2-27]: We are releasing the beta version of OpenING data via Google Drive. It is also noted that our Judge model IntJudge can be used for RL training, such as PPO or GRPO, for multimodal generation. Stay tuned!
🔥[2024-11-29]: We are releasing our judge model, IntJudge! If you wanna obtain the test results of your model on OpenING before the data is publicly available, please contact us via zpf4wp@outlook.com or zhangkaipeng@pjlab.org.cn. Stay tuned!
🚀[2024-11-28]: We are releasing our code, containing the evaluation pipeline on Interleaved Arena and the GPT-based evaluators! Stay tuned!
🔥[2024-11-27]: We are releasing our paper! The data will be openly available soon! Stay tuned!
We introduce GATE OpenING (OpenING), a comprehensive benchmark comprising 5,400 high-quality human-annotated instances across 56 real-world tasks. OpenING covers diverse daily scenarios such as travel guide, design, and brainstorming, offering a robust platform for challenging interleaved generation methods. In addition, we present IntJudge, a judge model for evaluating open-ended multimodal generation methods. Trained with a novel data pipeline, our IntJudge achieves an agreement rate of 82.42% with human judgments, outperforming GPT-based evaluators by 11.34%. Extensive experiments on OpenING reveal that current interleaved generation methods still have substantial room for improvement. Key findings on interleaved image-text generation are further presented to guide the development of next-generation generative models. We anticipate that more advanced multimodal judge models can be trained and tested on OpenING and we also believe that OpenING will push the boundaries of MLLMs towards general-purpose multimodal intelligence.
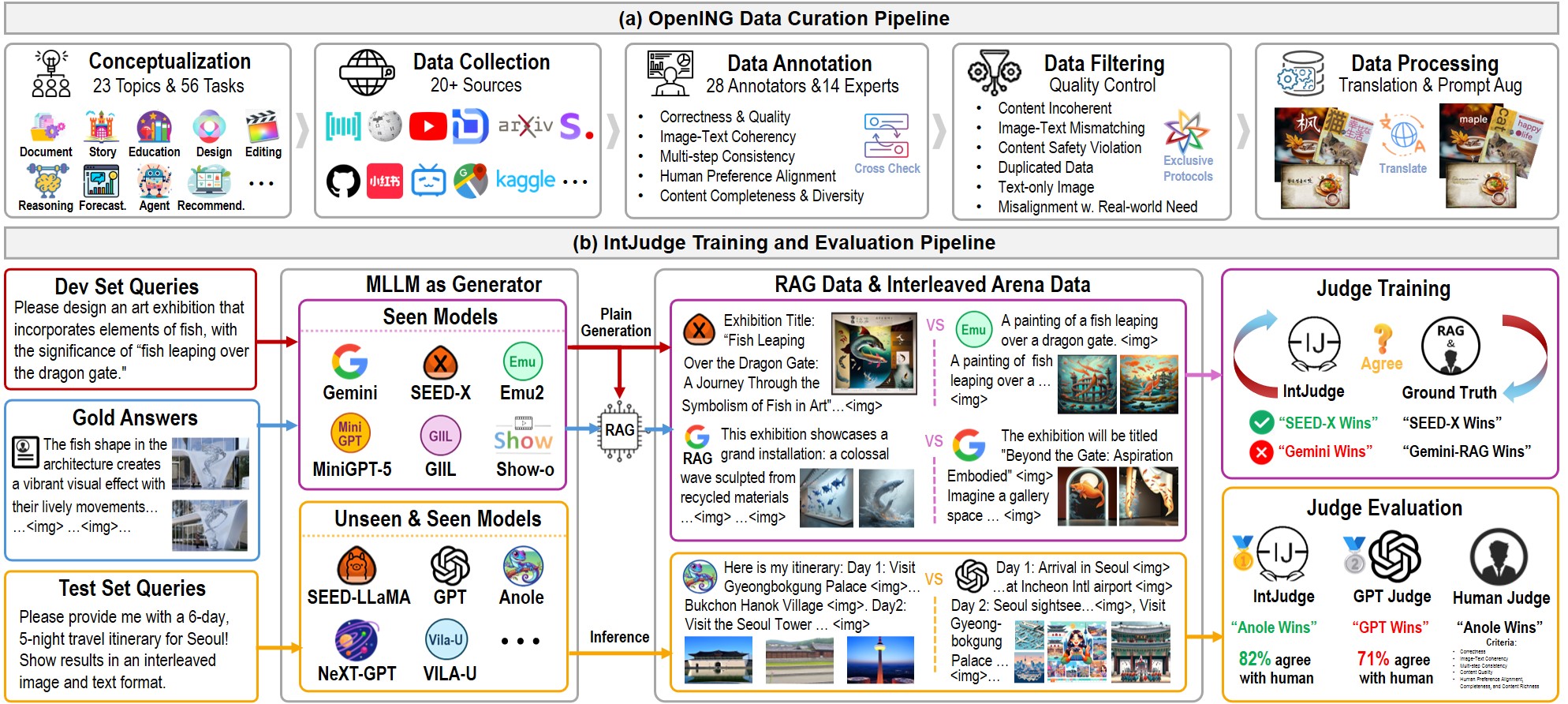
An illustration of our pipeline for data curation and the training of the proposed judge model, IntJudge. (a) We construct our OpenING benchmark in a top-down manner, which involves five stages: conceptualization, data collection, annotation, filtering, and processing. (b) We use the Dev Set of OpenING to train the proposed IntJudge. Specifically, we propose an Interleaved Arena to facilitate training data annotation and a novel Reference-Augmented Generation (RAG) approach to expand the training data size. We evaluate both seen and unseen interleaved image-text generation methods on the Test Set of OpenING to compare IntJudge with human judgments and GPT-4o judgments.
OpenING includes 5,400 instances of multi-step interleaved image-text content across 23 meta-topics and 56 tasks, with diverse, carefully designed queries for various topics. Compared with the existing benchmarks. OpenING includes more comprehensive data and broader tasks, providing multiple robost evaluation methods including an openly available judge model IntJudge. Steps: a step is indicated by an input instruction or an output image-text pair; SpI: Steps per Instance.

We evaluate 12 representative methods, grouping them into three categories: 1) Integrated Pipeline, which in volves separate models for text and image generation in two stages; 2) Two-Stage Generator, which employs a unified model architecture to produce text and images in separate stages; and 3) End-to-End Generator, which directly generates image-text outputs in a single step. We reserve GPT-4o+DALL-E3, Emu3, VILA-U, Anole, SEED-LLaMA, and NExT-GPT as unseen models for IntJudge validation, while the remaining models are regarded as seen models in IntJudge training. We compare the interleaved content generated by 12 baseline methods with answers from human expert and rank these methods by win rates evaluated by human judgements.
Comparison of model win rates evaluated by human, GPT-4o, and our IntJudge under FDT and different tie metrics. FDT: Force Dividing Tie metric. w/o Tie: Non-tie case. w/ Tie (0) and w/ Tie (.5): Count a tie as 0 and 0.5 wins for a model in a pairwise comparison, respectively. The best-performing model in each category is in-bold, and the second best is underlined.
| Method | Human Evaluation | GPT Evaluation | IntJudge Evaluation | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FDT | w/o Tie | w/ Tie (0) | w/ Tie (.5) | FDT | w/o Tie | w/ Tie (0) | w/ Tie (.5) | FDT | w/o Tie | w/ Tie (0) | w/ Tie (.5) | |
Detailed scores from GPT-based evaluations are also provided to support explainable performance analysis of different models. However, GPT-4o showcases the inherent biases to its own generation results. For example, GPT-4o gives high Human Preference Alignment scores to its own answers, though the human annotators do not agree with that. Moreover, the subjective scores based on GPT-4o are not very stable, especially with the update of GPT versions.
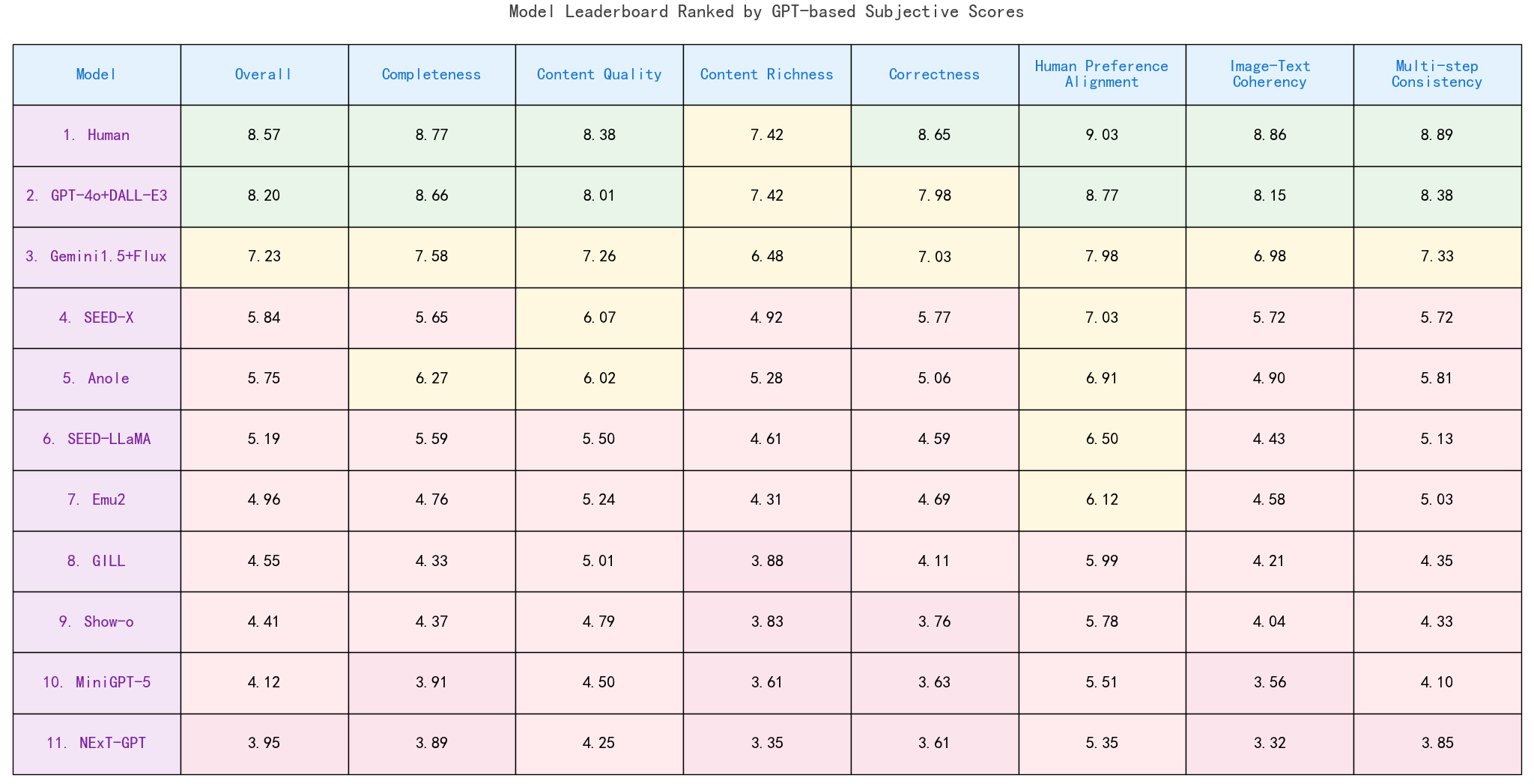
Evaluation results of GPT-based subjective scores.
We present the agreement between different evaluators and human judgments. We implement random guess (Random) as a baseline. The results indicate that IntJudge generally achieved higher agreement with human judgments (82.42% in FDT) compared to GPT-based evaluation (71.08% in FDT), suggesting its potential for scalable evaluation of interleaved image-text generation.

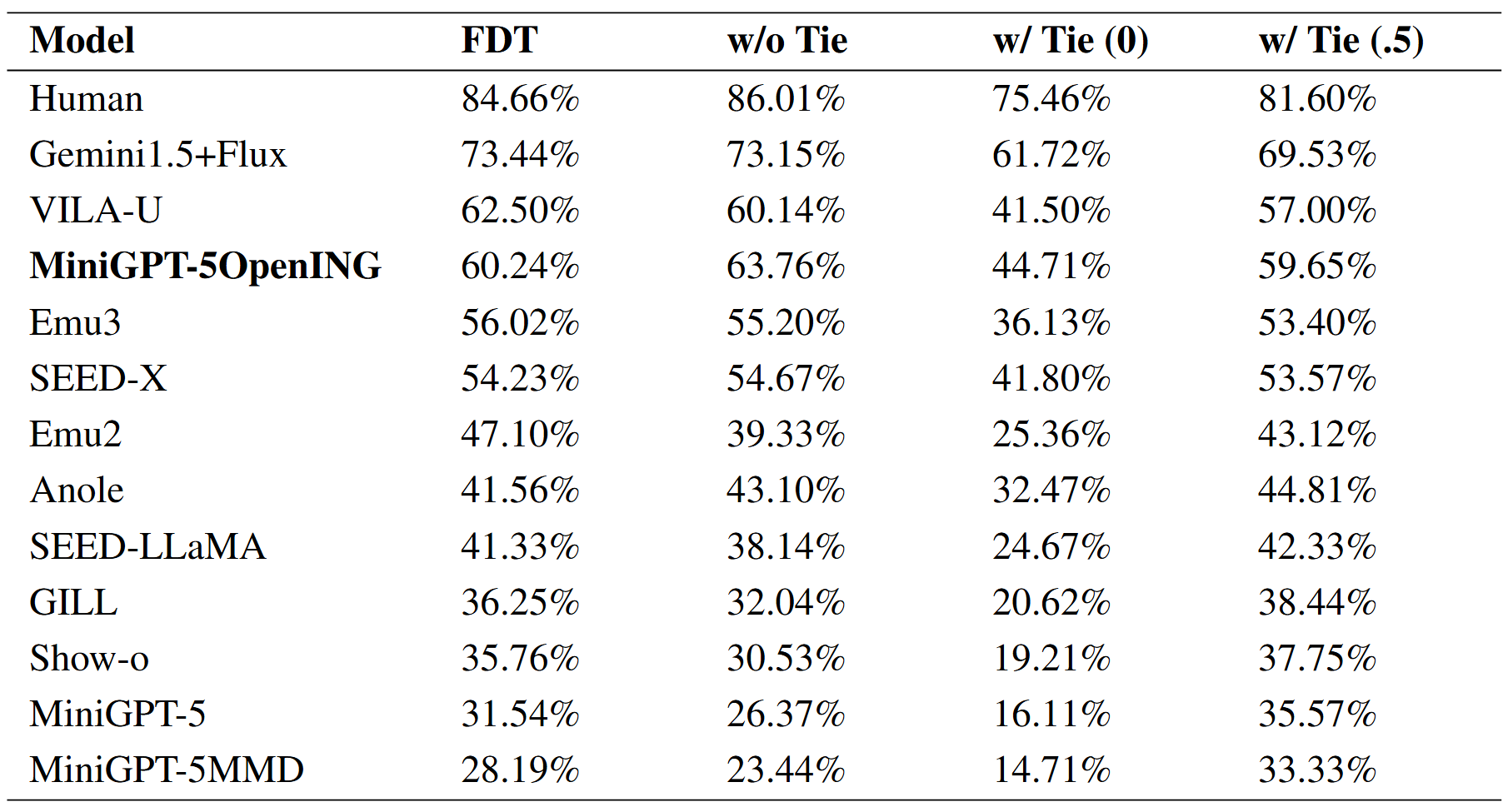
The Dev Set of OpenING can provide 3,260 training instances as a special training set for fine-tuning the interleaved generation method. We finetuned MiniGPT-5 on the Dev Set to evaluate if fine-tuning improves interleaved generation performance. MiniGPT-5OpenING (finetuned on OpenING) is compared to other state-of-the-art models and MiniGPT-5 baselines (MiniGPT-5 is finetuned on VIST and MiniGPT-5MMD is finetuned on MMDialog). IntJudge-based evaluation on 2,160 randomly sampled pairwise outputs MiniGPT-5OpenING outperforms the baselines, with a 37.39% relative improvement on w/o Tie metric. These results demonstrate that training on OpenING's specialized dataset enhances the model's contextual understanding and ability to generate coherent interleaved image-text content.
We conduct an error analysis on 200 instances where generative models underperformed compared to human experts. The frequency of error types across three models reveals their specific performance limitations. GPT-4o+DALL-E3 suffers from content incoherency and inconsistency since it is hard for DALL-E3 to generate multiple images in the same style. Poor image quality is the main problem of Anole, as its finetuning data for image generation is insufficient. While most outputs by SEED-X have multiple errors, the inexistence of text or image content is still the major problem.
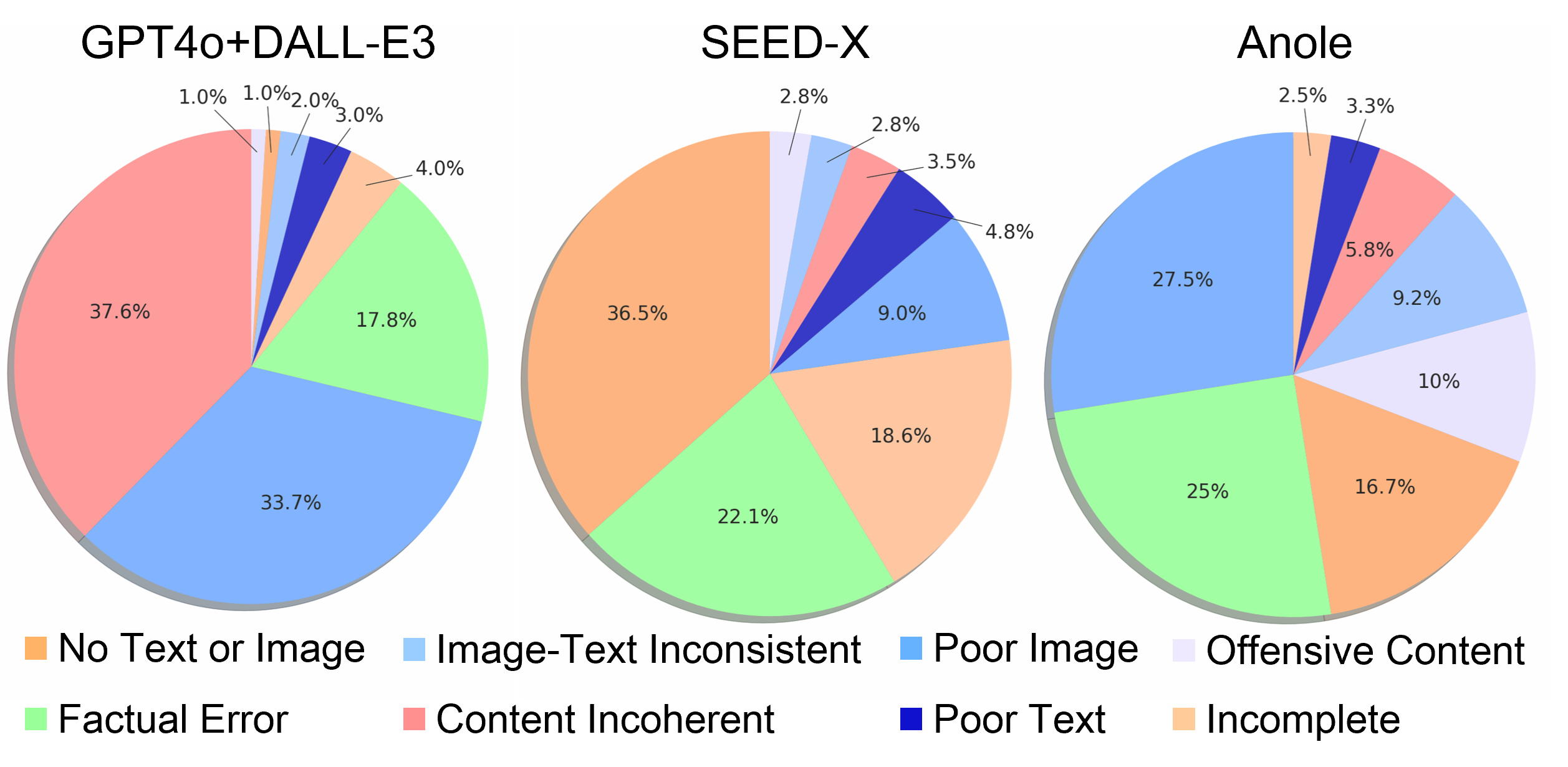
Error distribution of three models: GPT-4o+DALL-E3 (Integrated Pipeline), SEED-X (Two-Stage Generator), and Anole (End-to-End Generator).

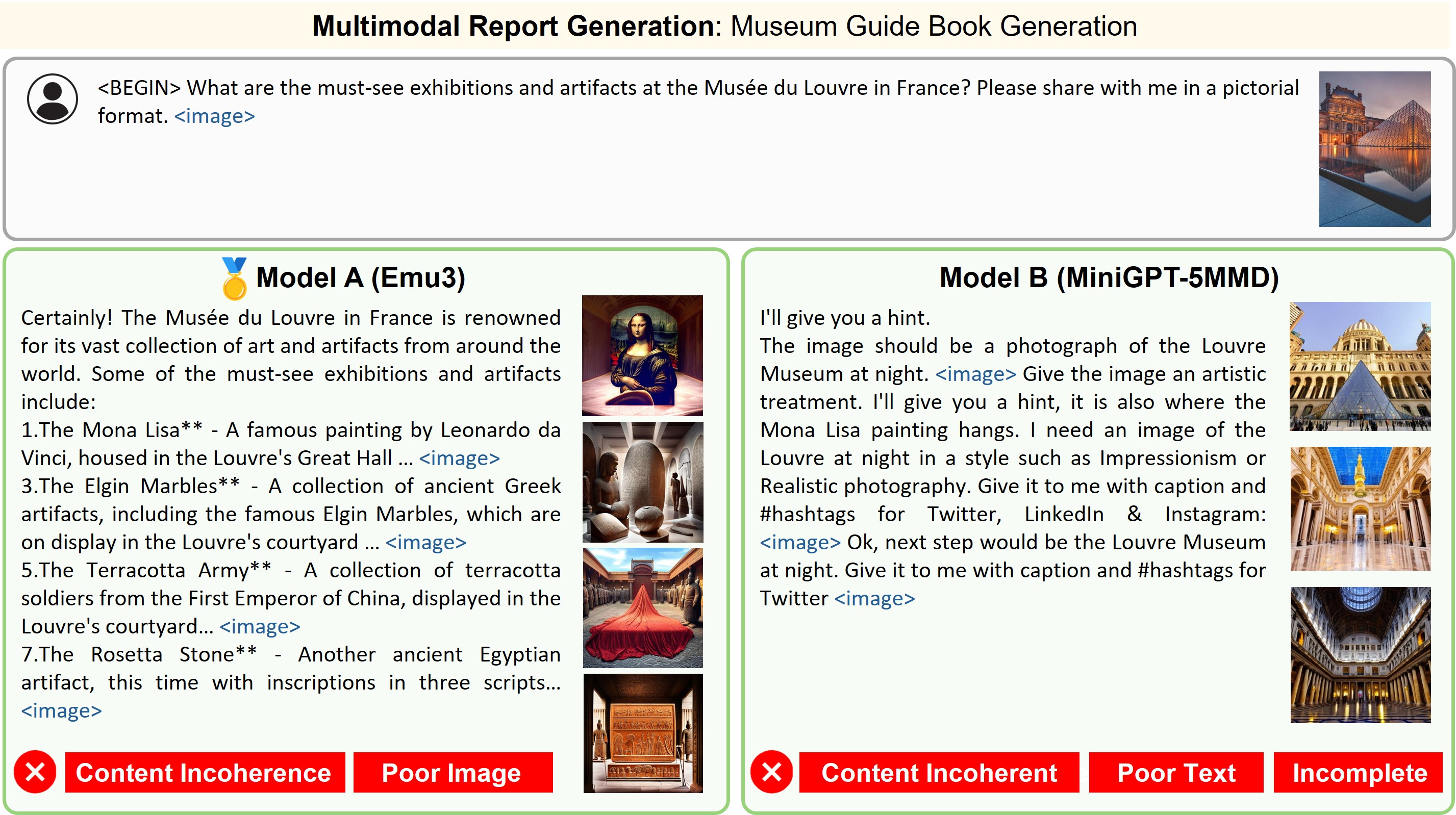
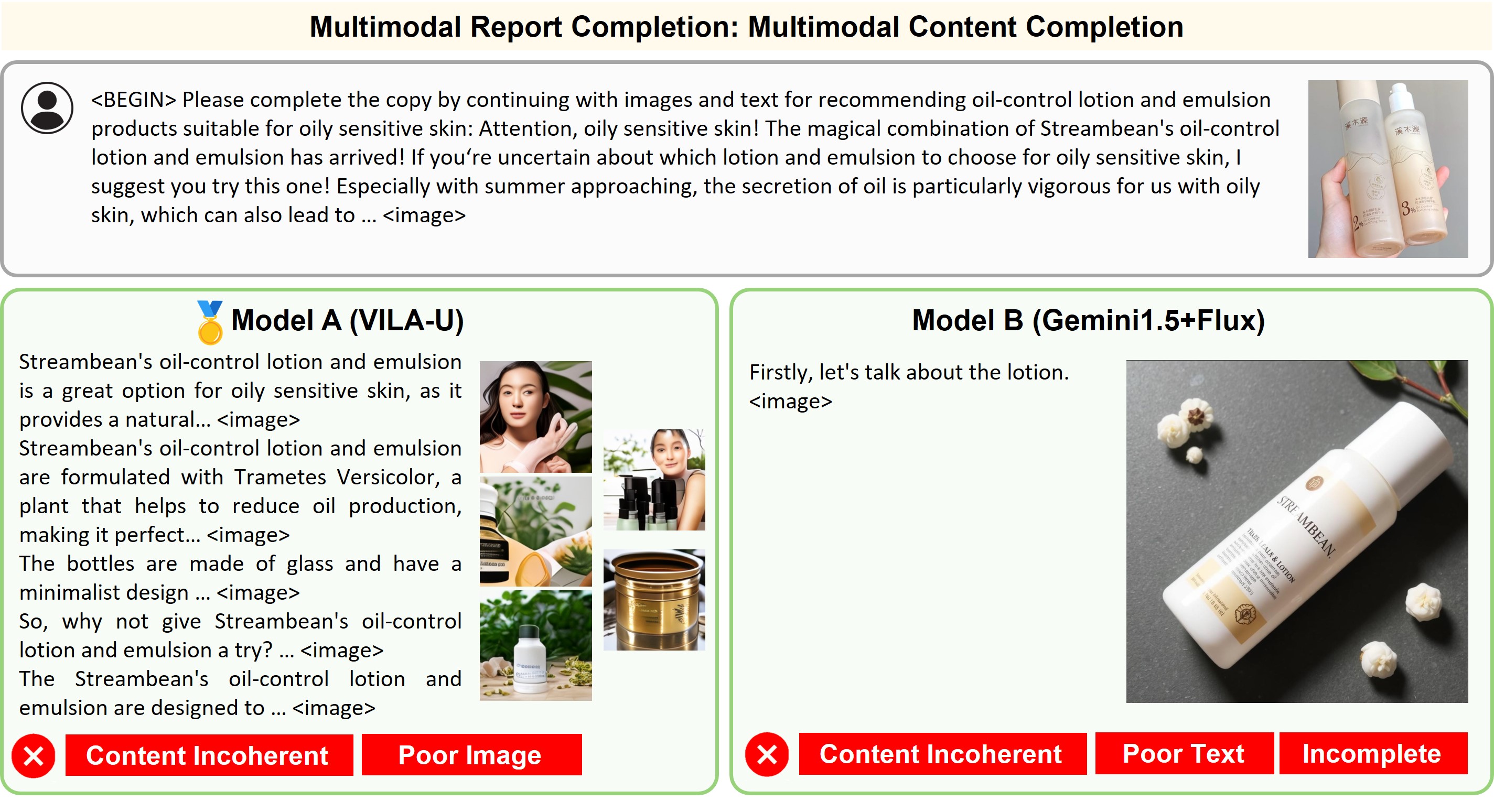

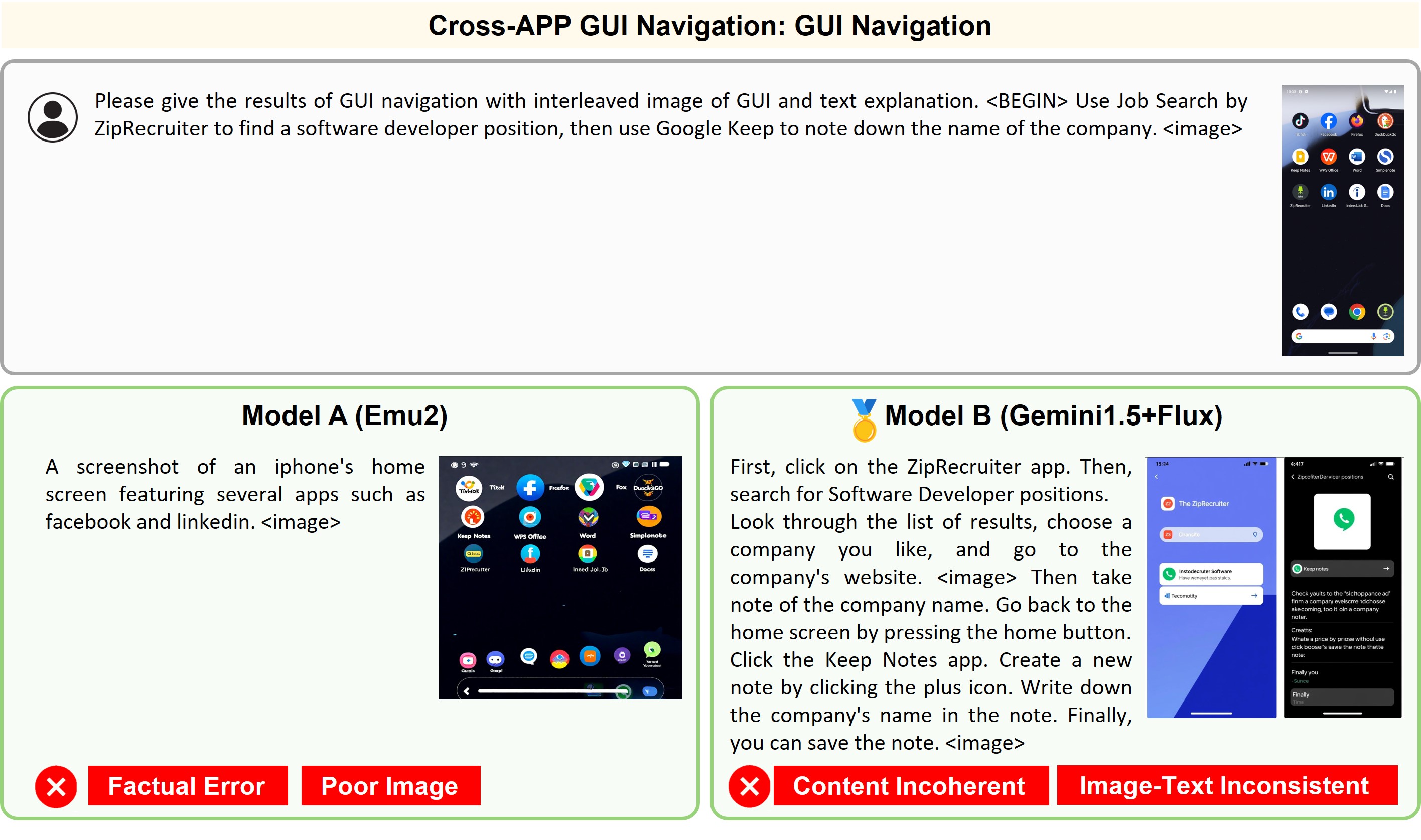
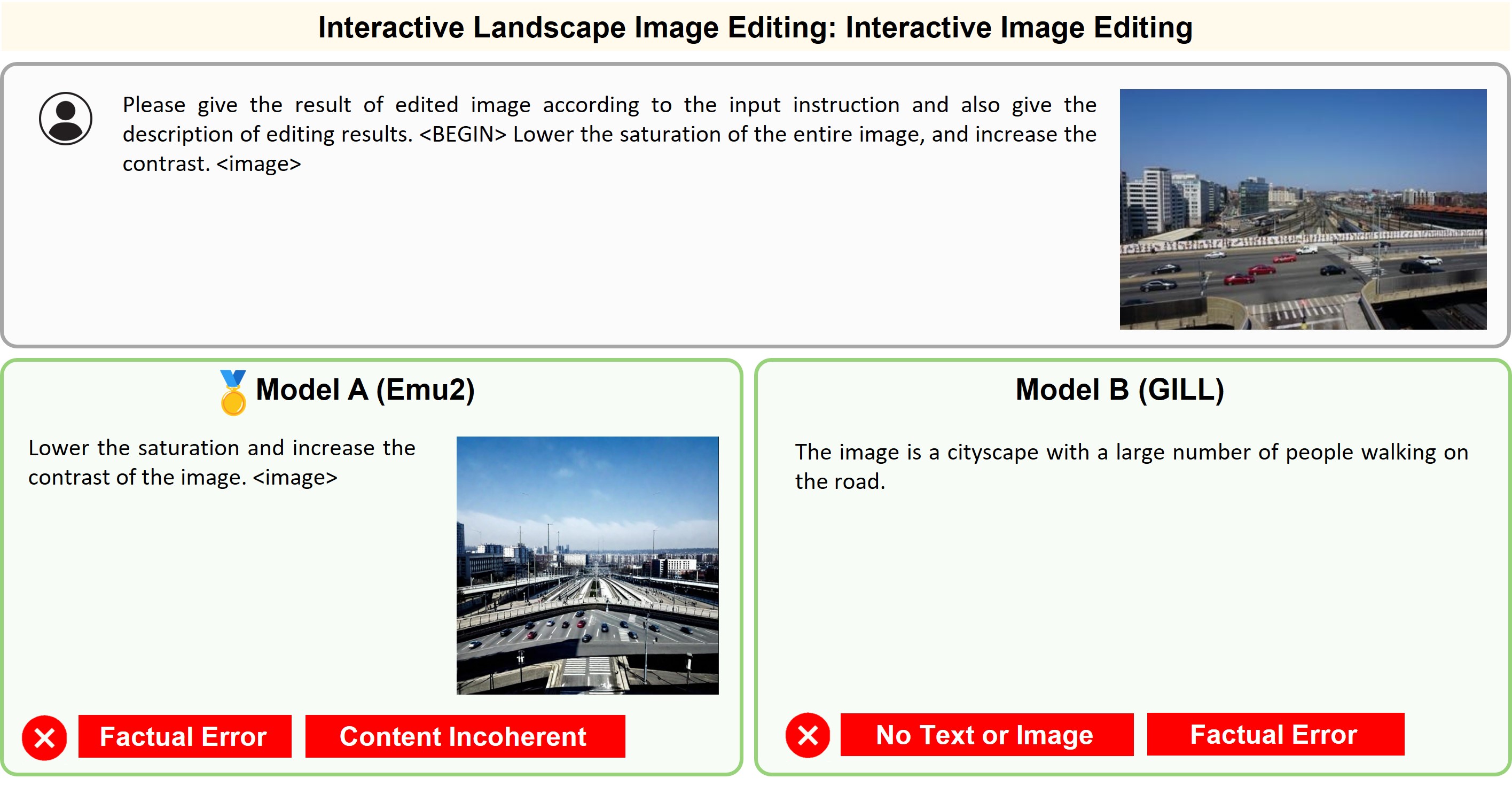


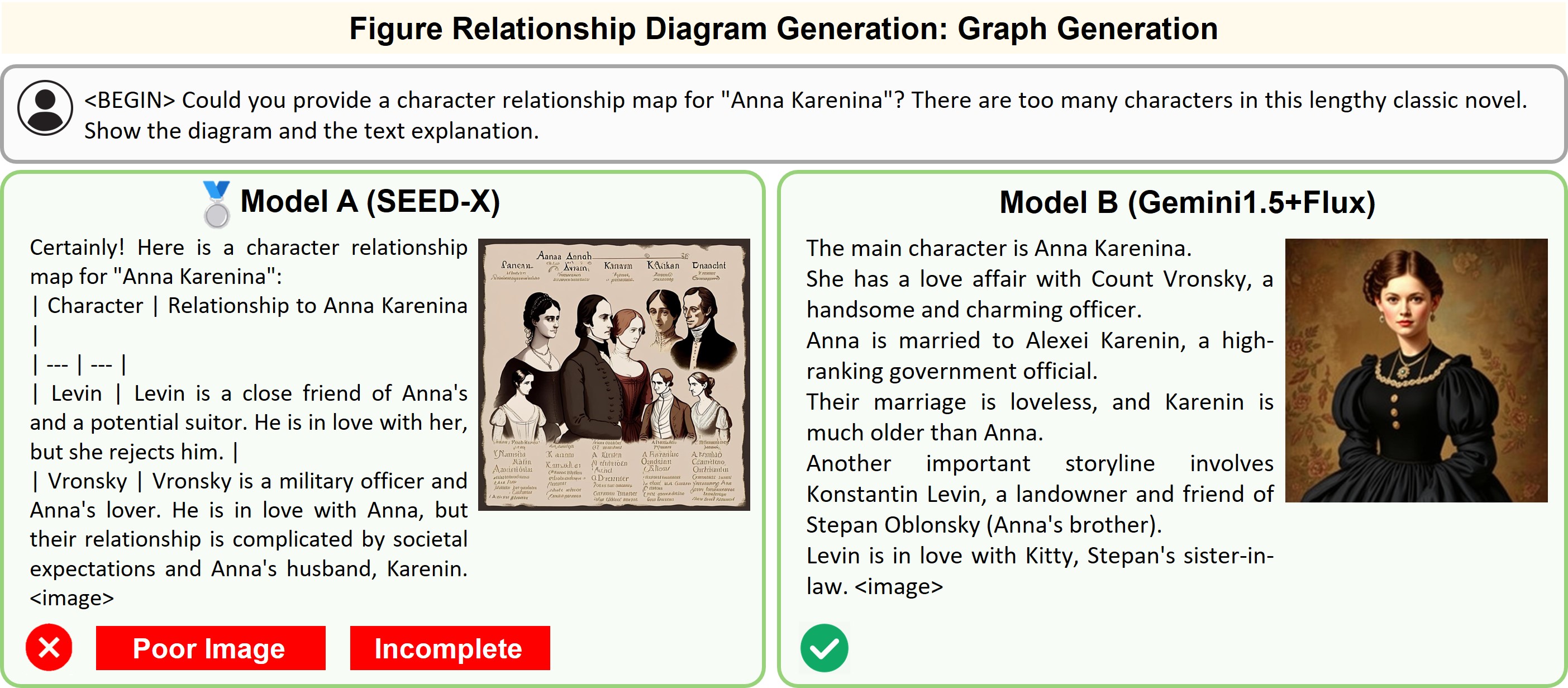



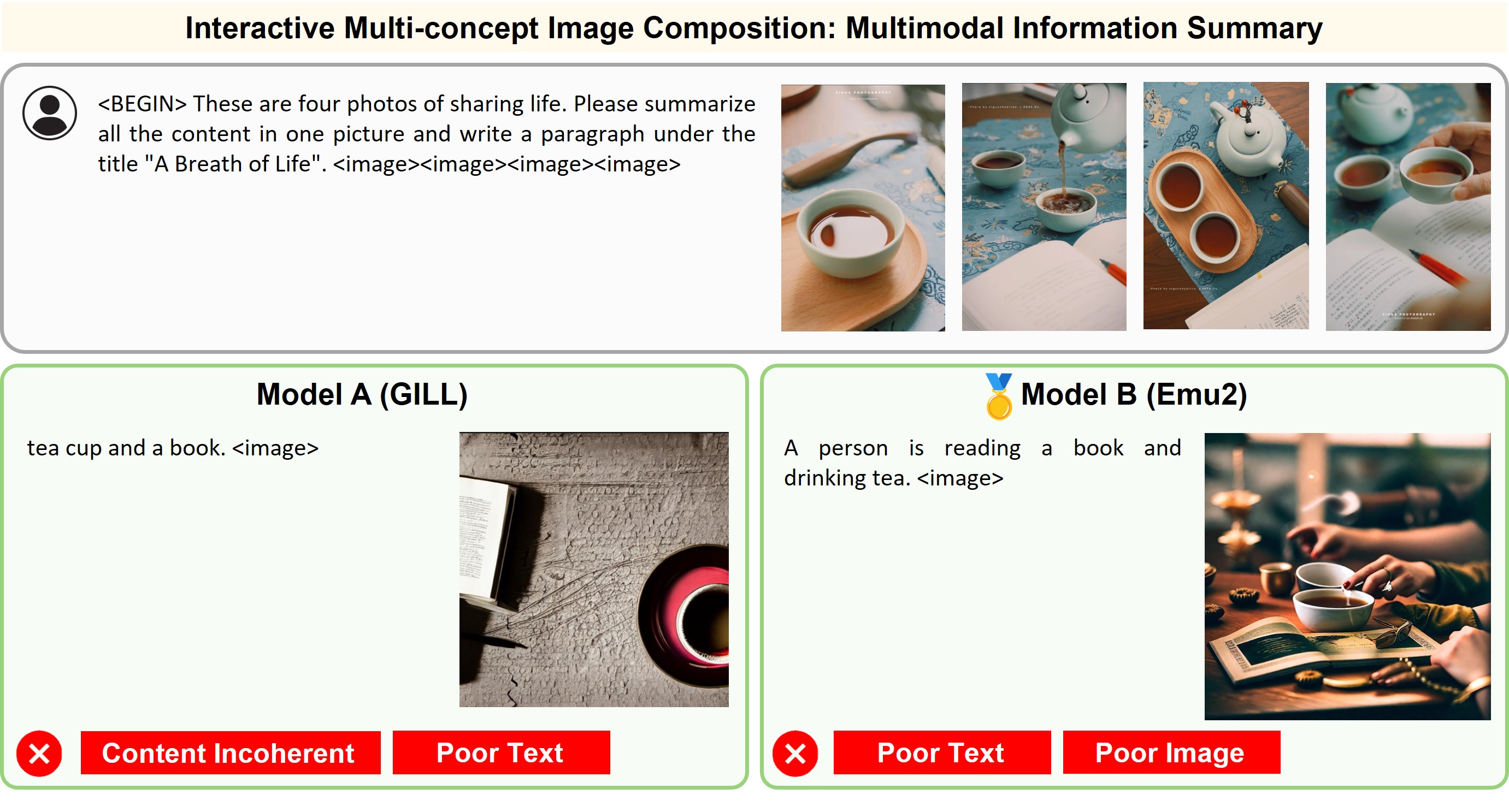
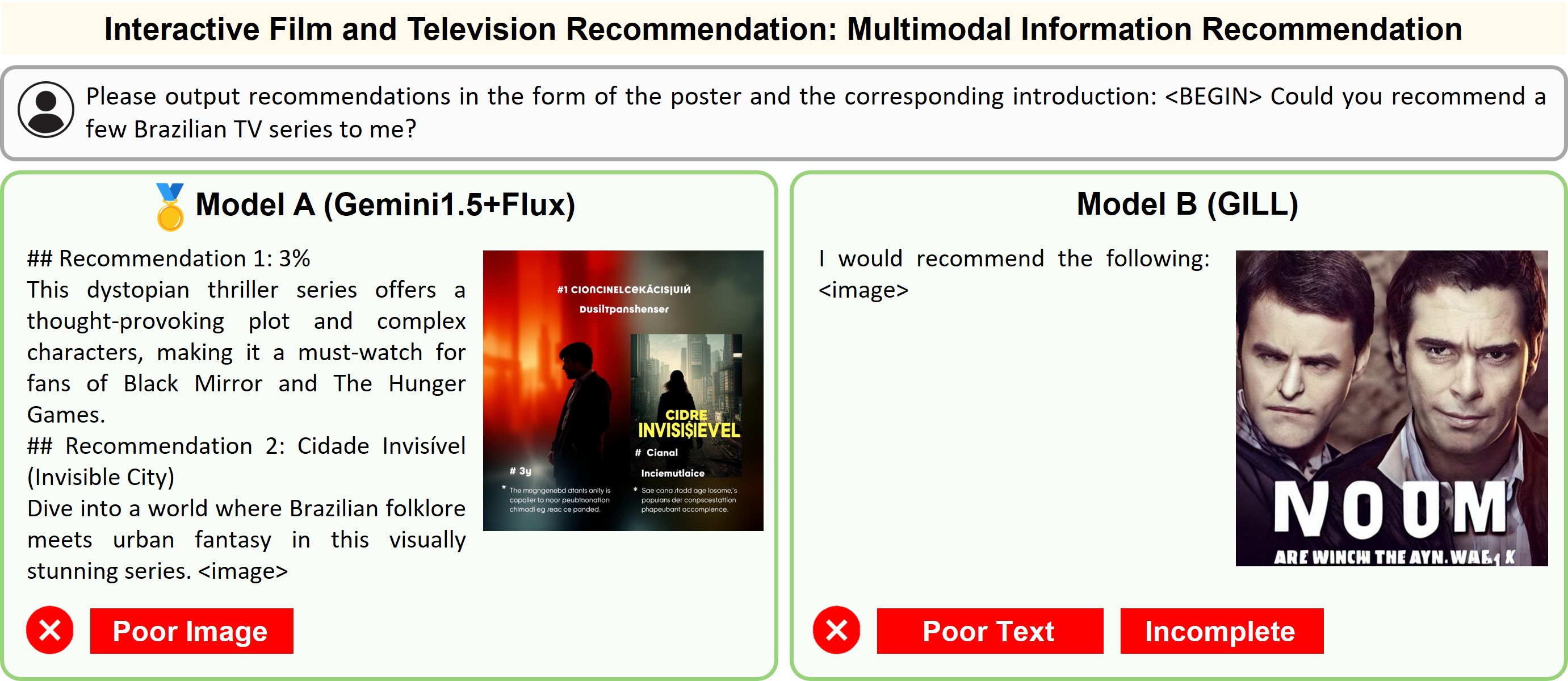
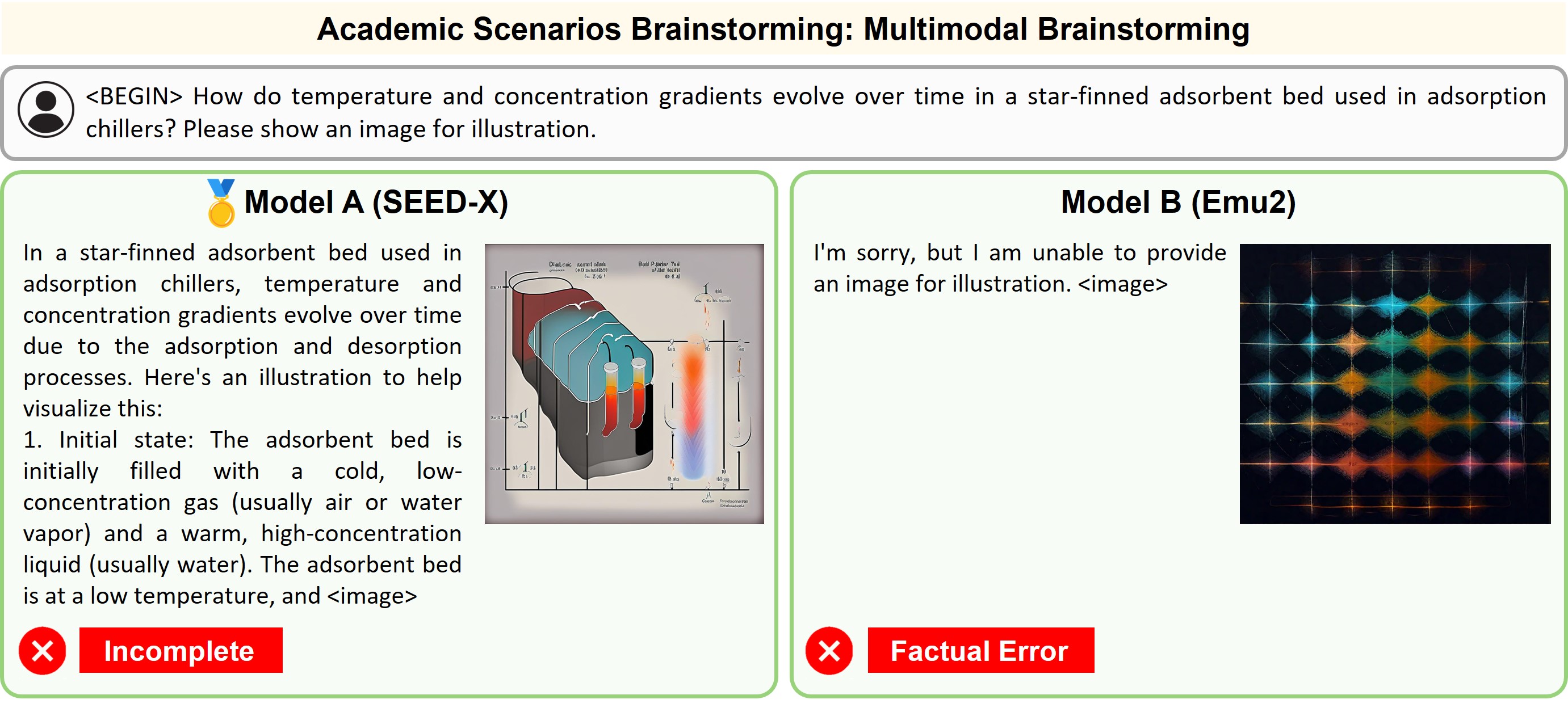

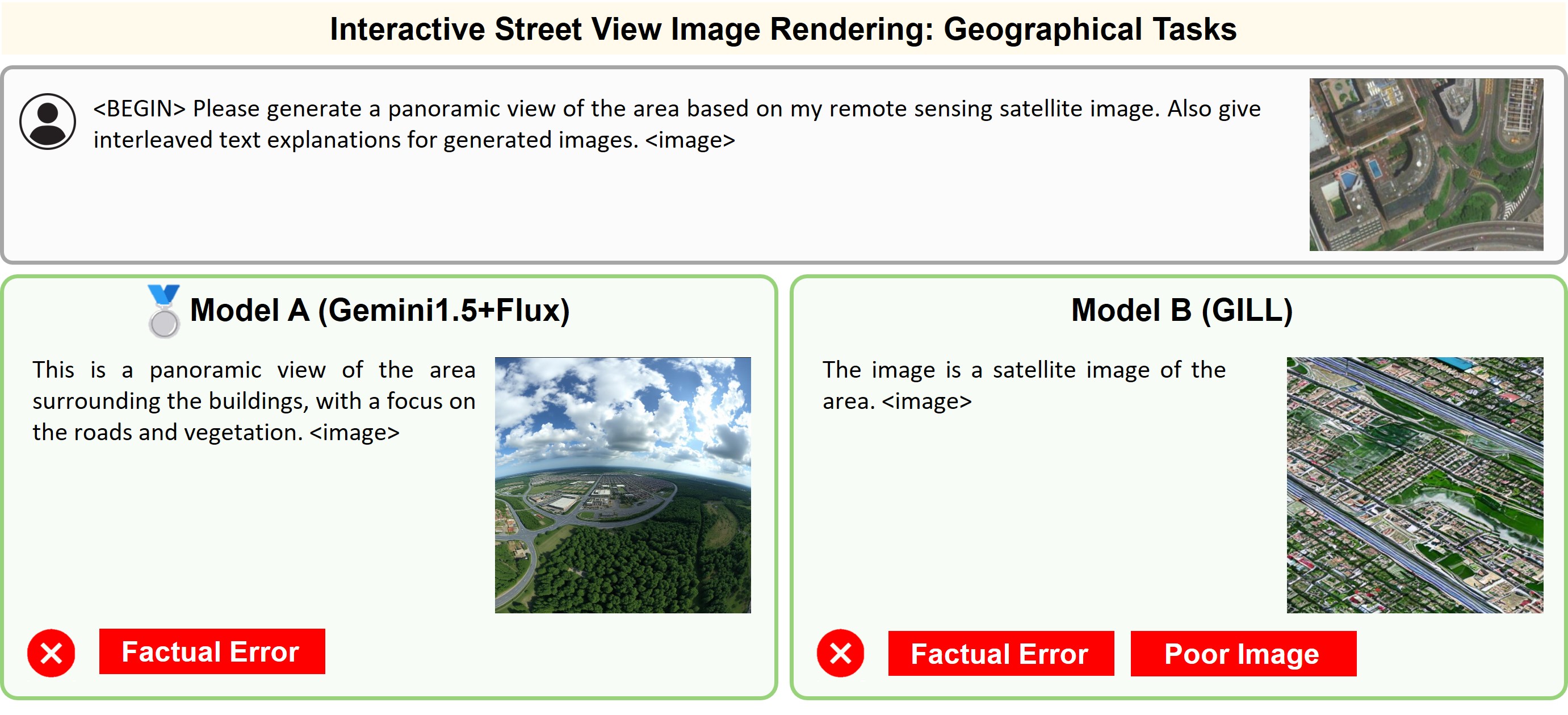
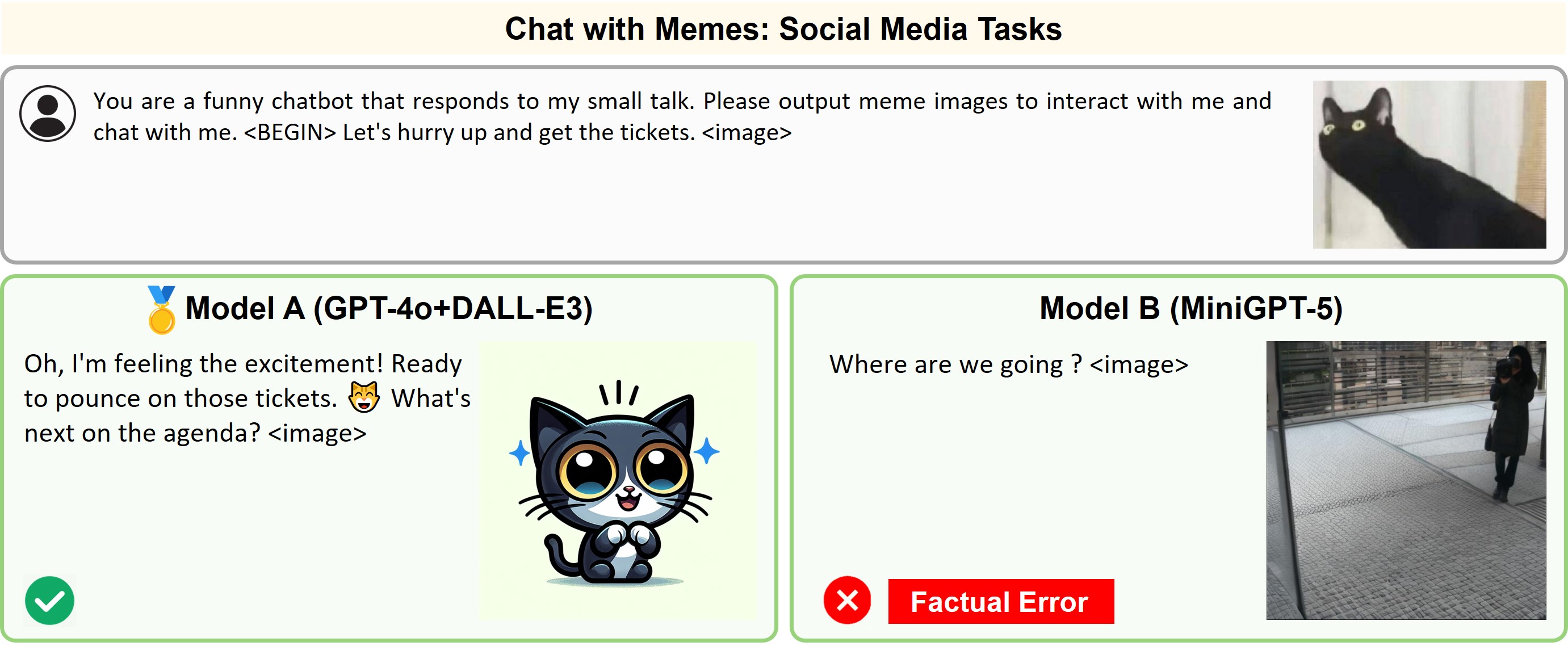

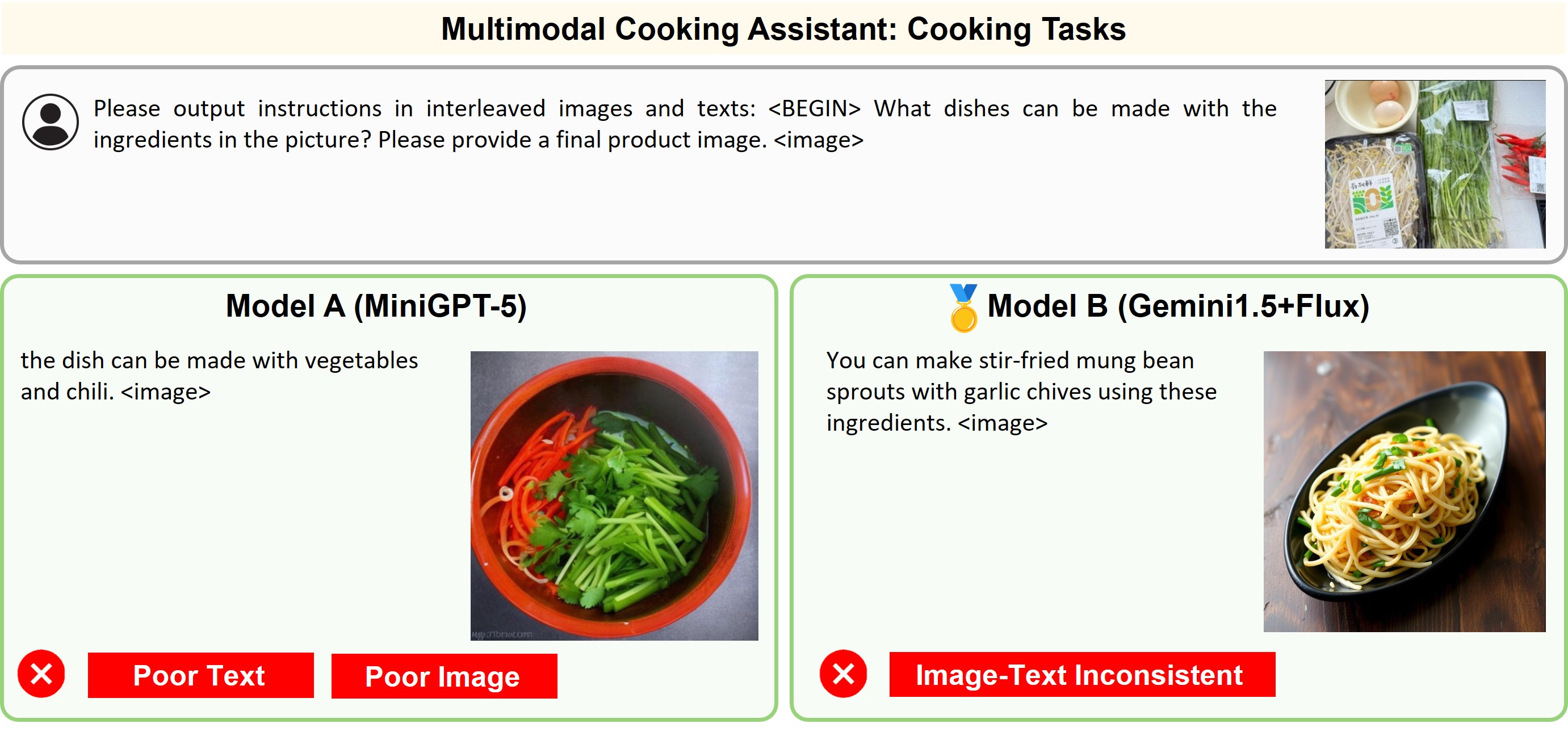


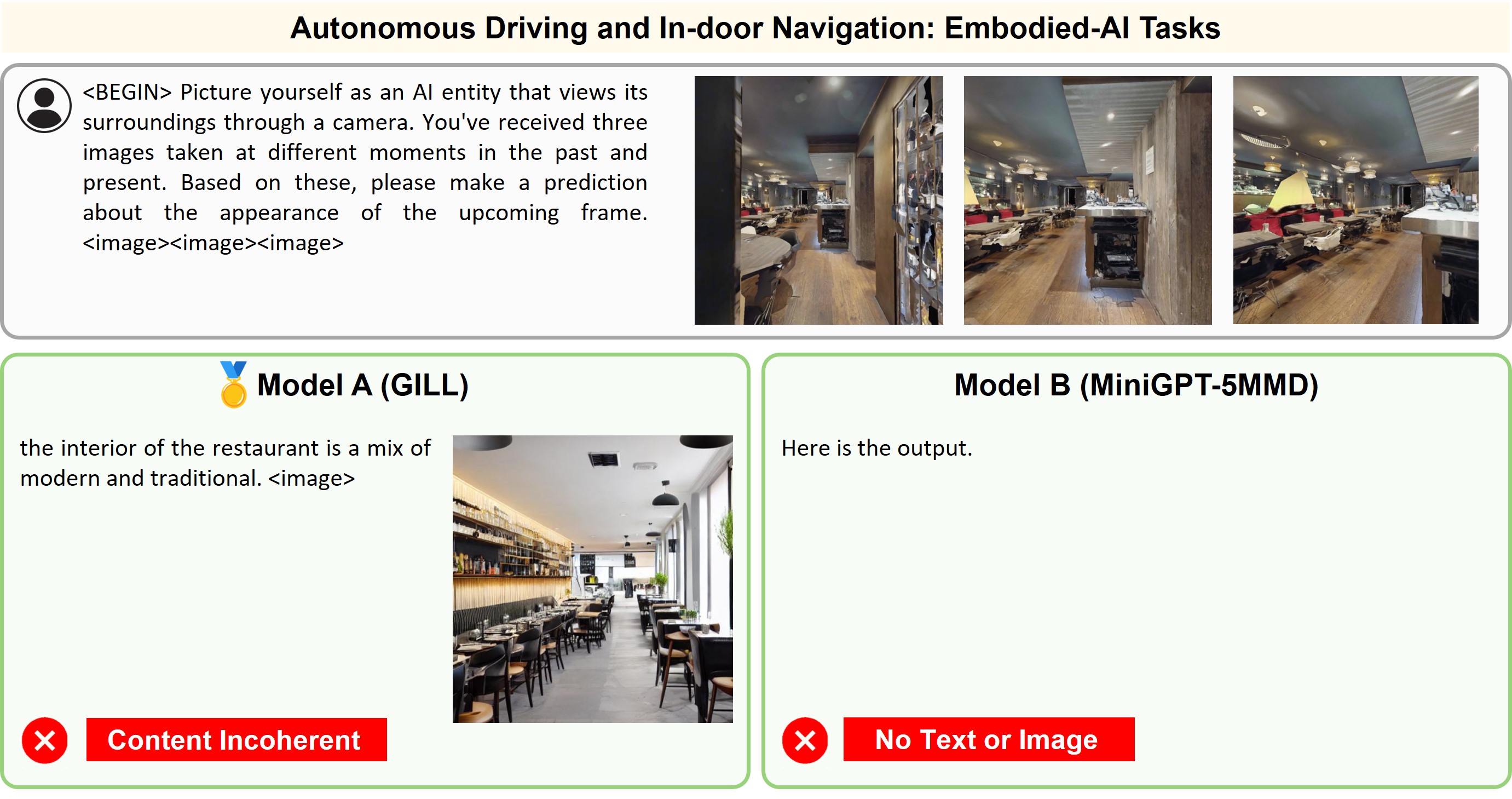
Illustration of 23 pairs of generated outputs across 23 meta-topics. The gold medal represents the winner of pairwise comparison and the silver medal denotes a more favorable output in a tie scene of the pairwise comparison.
@inproceedings{zhou2025opening,
title={OpenING: A Comprehensive Benchmark for Judging Open-ended Interleaved Image-Text Generation},
author={Zhou, Pengfei and Peng, Xiaopeng and Song, Jiajun and Li, Chuanhao and Xu, Zhaopan and Yang, Yue and Guo, Ziyao and Zhang, Hao and Lin, Yuqi and He, Yefei and others},
booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference},
pages={56--66},
year={2025}
}
